How to Synthesize Text Data without Model Collapse?
ICML · 2025 · arXiv: arxiv.org/abs/2412.14689
Abstract
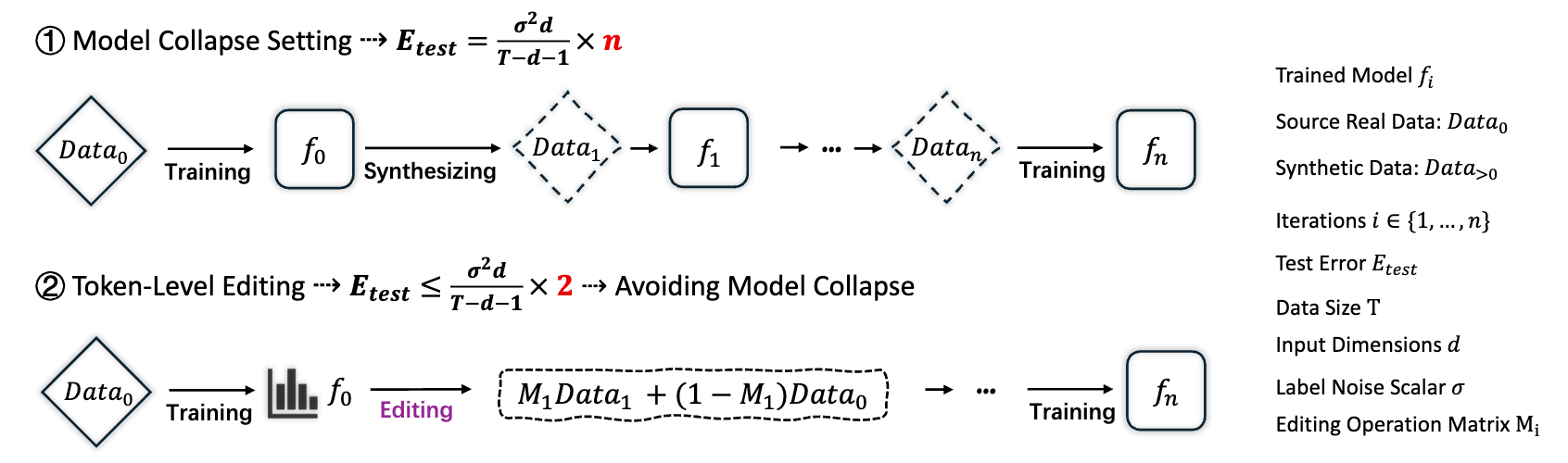
Model collapse in synthetic data indicates that iterative training on self-generated data leads to a gradual decline in performance. With the proliferation of AI models, synthetic data will fundamentally reshape the web data ecosystem. Future GPT-{n} models will inevitably be trained on a blend of synthetic and human-produced data. In this paper, we focus on two questions: what is the impact of synthetic data on language model training, and how to synthesize data without model collapse? We first pre-train language models across different proportions of synthetic data, revealing a negative correlation between the proportion of synthetic data and model performance. We further conduct statistical analysis on synthetic data to uncover distributional shift phenomenon and over-concentration of n-gram features. Inspired by the above findings, we propose token editing on human-produced data to obtain semi-synthetic data. As a proof of concept, we theoretically demonstrate that token-level editing can prevent model collapse, as the test error is constrained by a finite upper bound. We conduct extensive experiments on pre-training from scratch, continual pre-training, and supervised fine-tuning. The results validate our theoretical proof that token-level editing improves data quality and enhances model performance.
Citation
@inproceedings{zhu2025toedit,
title={How to Synthesize Text Data without Model Collapse?},
author={Zhu, Xuekai and Cheng, Daixuan and Li, Hengli and Zhang, Kaiyan and Hua, Ermo and Lv, Xingtai and Ding, Ning and Lin, Zhouhan and Zheng, Zilong and Zhou, Bowen},
booktitle = {Proceedings of the 42nd International Conference on Machine Learning},
year={2025}
}