TokenSwift: Lossless Acceleration of Ultra Long Sequence Generation
ICML · 2025 · arXiv: arxiv.org/abs/2502.18890
Abstract
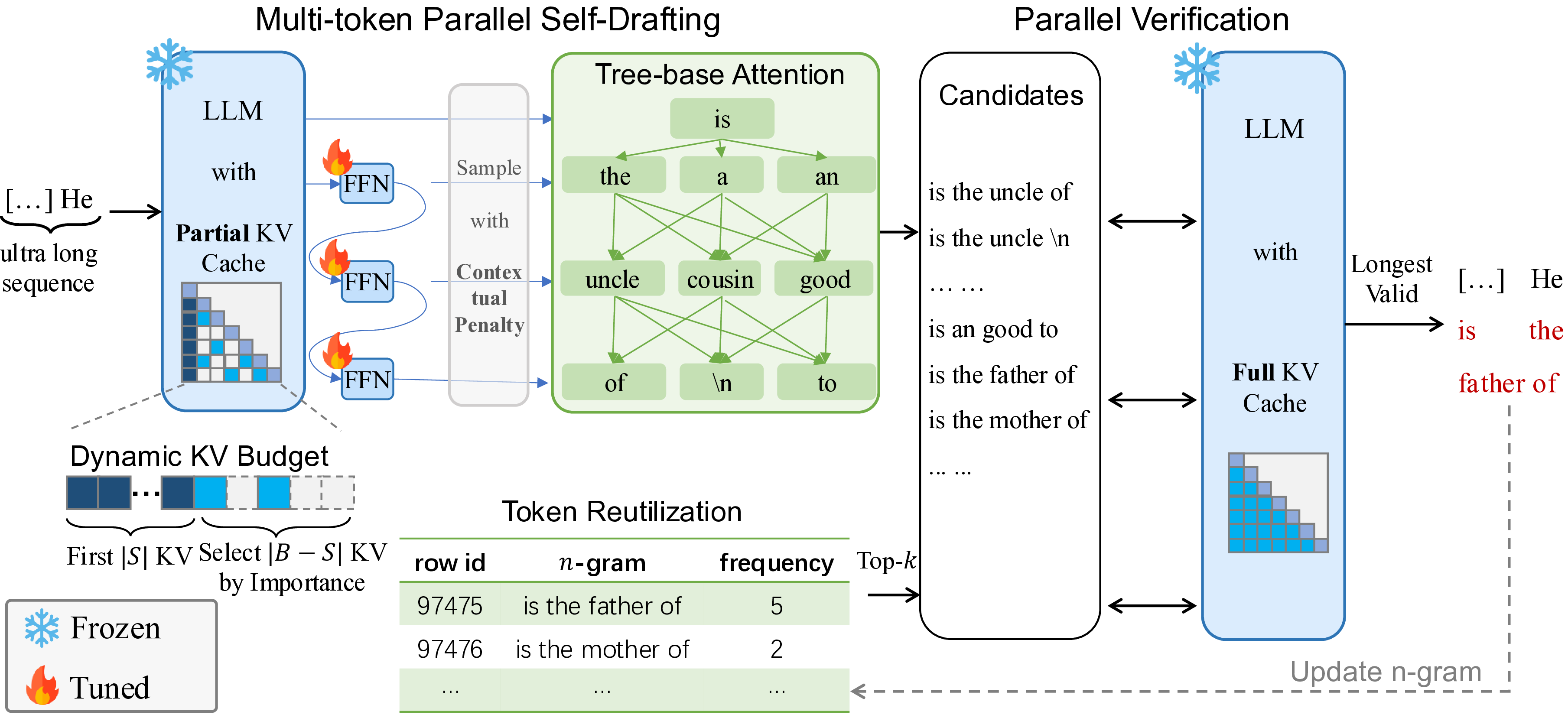
Generating ultra-long sequences with large language models (LLMs) has become increasingly crucial but remains a highly time-intensive task, particularly for sequences up to 100K tokens. While traditional speculative decoding methods exist, simply extending their generation limits fails to accelerate the process and can be detrimental. Through an in-depth analysis, we identify three major challenges hindering efficient generation: frequent model reloading, dynamic key-value (KV) management and repetitive generation. To address these issues, we introduce TOKENSWIFT, a novel framework designed to substantially accelerate the generation process of ultra-long sequences while maintaining the target model’s inherent quality. Experimental results demonstrate that TOKENSWIFT achieves over 3 times speedup across models of varying scales (1.5B, 7B, 8B, 14B) and architectures (MHA, GQA). This acceleration translates to hours of time savings for ultra-long sequence generation, establishing TOKENSWIFT as a scalable and effective solution at unprecedented lengths. Code can be found at this URL.
Citation
@inproceedings{wu2025tokenswift,
title={TokenSwift: Lossless Acceleration of Ultra Long Sequence Generation},
author={Wu, Tong and Shen, Junzhe and Jia, Zixia and Wang, Yuxuan and Zheng, Zilong},
booktitle = {Proceedings of the 42nd International Conference on Machine Learning},
year={2025}
}