TokenSwift: Lossless Acceleration of Ultra Long Sequence Generation
ICML · 2025 · arXiv: arxiv.org/abs/2502.18890
Abstract
Generating ultra-long sequences with large language models (LLMs) has become increasingly crucial but remains a highly time-intensive task, particularly for sequences up to 100K tokens. While traditional speculative decoding methods exist, simply extending their generation limits fails to accelerate the process and can be detrimental. Through an in-depth analysis, we identify three major challenges hindering efficient generation: frequent model reloading, dynamic key-value (KV) management and repetitive generation. To address these issues, we introduce TOKENSWIFT, a novel framework designed to substantially accelerate the generation process of ultra-long sequences while maintaining the target model’s inherent quality. Experimental results demonstrate that TOKENSWIFT achieves over 3 times speedup across models of varying scales (1.5B, 7B, 8B, 14B) and architectures (MHA, GQA). This acceleration translates to hours of time savings for ultra-long sequence generation, establishing TOKENSWIFT as a scalable and effective solution at unprecedented lengths. Code can be found at this URL.
Recent advances in large language models (LLMs), amplified by their long context capacities, have demonstrated remarkable proficiency in intricate reasoning (OpenAI-o1; DeepSeek-R1), agentic thinking (Reflexion; ReAct; RAM), and creative writing (Wang et al., 2023; Mikhaylovskiy, 2023), etc. These advancements necessitate the ability to generate lengthy sequences, e.g., o1-like reasoning tends to generate protracted chain-of-thought trajectories before reaching final conclusions.
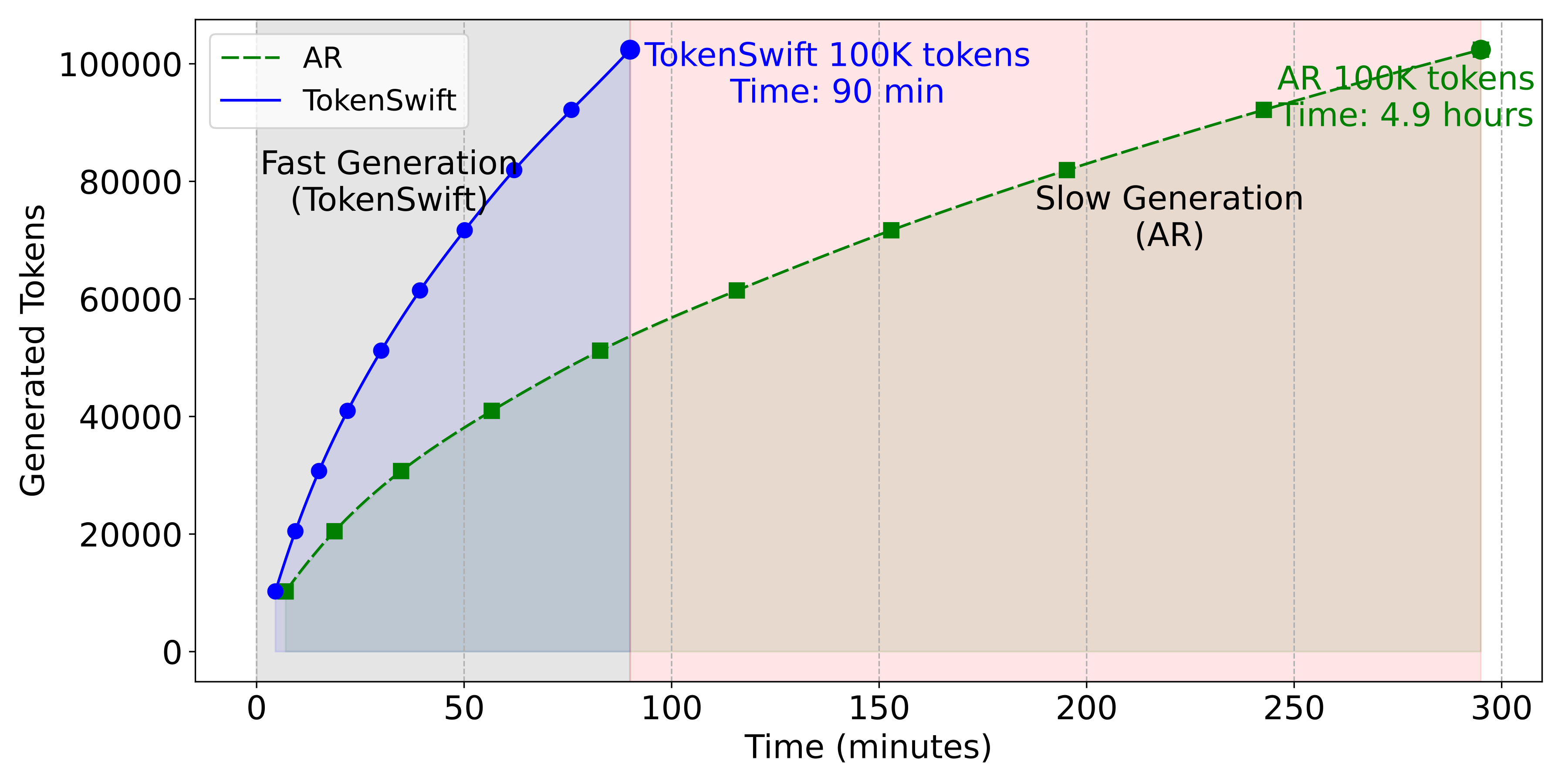
However, generating ultra-long sequences (up tp 100K tokens) is painfully slow. For example, generating 100K tokens with LLaMA3.1-8B can take approximately five hours (Figure 2), hindering real-world applications.
Is Speculative Decoding Enough?
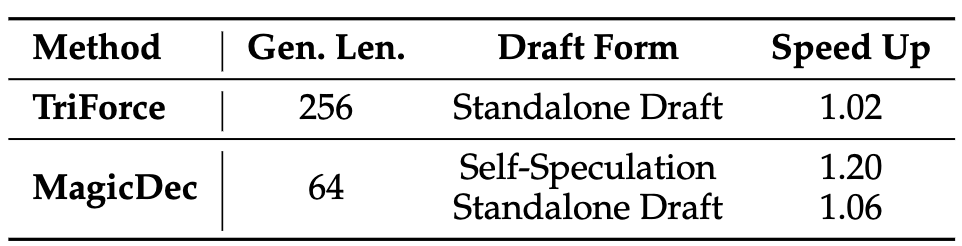
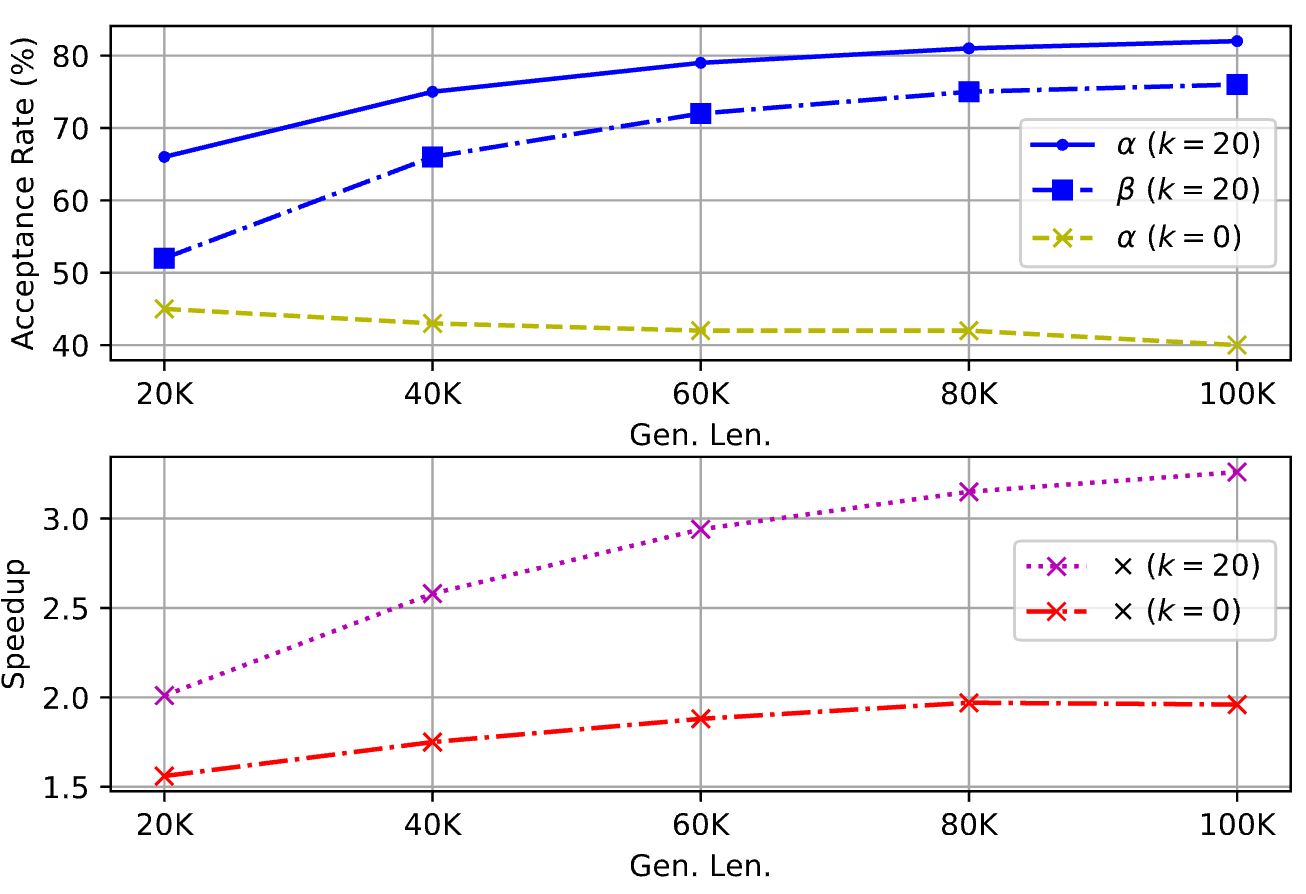
A straightforward solution is to take advantage of recent success in speculative decoding (SD). However, existing methods are generally tailored for generating short sequences, e.g., TriForce and MagicDec are limited to generating 256 and 64 tokens, respectively. Directly extending their generation length to 100K tokens would inevitably encounter failures due to KV cache budget constraints. Furthermore, when applied to optimized KV cache architectures such as Group Query Attention (GQA), these methods yield only marginal acceleration gains for short-sequence generation (Figure 3). This observation leads to a pivotal research question:
Is it possible to achieve model-agnostic lossless accelerations, akin to those seen in short-sequence SDs, for generating ultra-long sequences, with minimal training overhead?
Why Ultra-Long Sequences Are a Headache
Generating ultra-long sequences exposes three critical bottlenecks:
- Frequent Model Reloading: When generating ultra-long sequence, such as 100K tokens, the GPU must reload the model weights over 100,000 times. This repetitive process poses the challenge: How can we reduce the frequency of model reloading?
- Prolonged Growing of KV Cache: TriForce and MagicDec have demonstrated that a small KV cache budget can be used during the drafting phase. While their one-time compression strategy at the prefill stage can handle scenarios with long prefixes and short outputs, it fails to address cases involving ultra-long outputs. The challenge lies in determining when and how to dynamically update the KV cache within limited budget.
- Repetitive Content Generation: When generating sequences of considerable length, e.g., 100K, the model tends to produce repetitive sentences. While eliminating this issue is not our focus, it is still essential and challenging to mitigate repetition patterns in ultra-long sequences.
TokenSwift: Tailored Solutions for Each Challenge
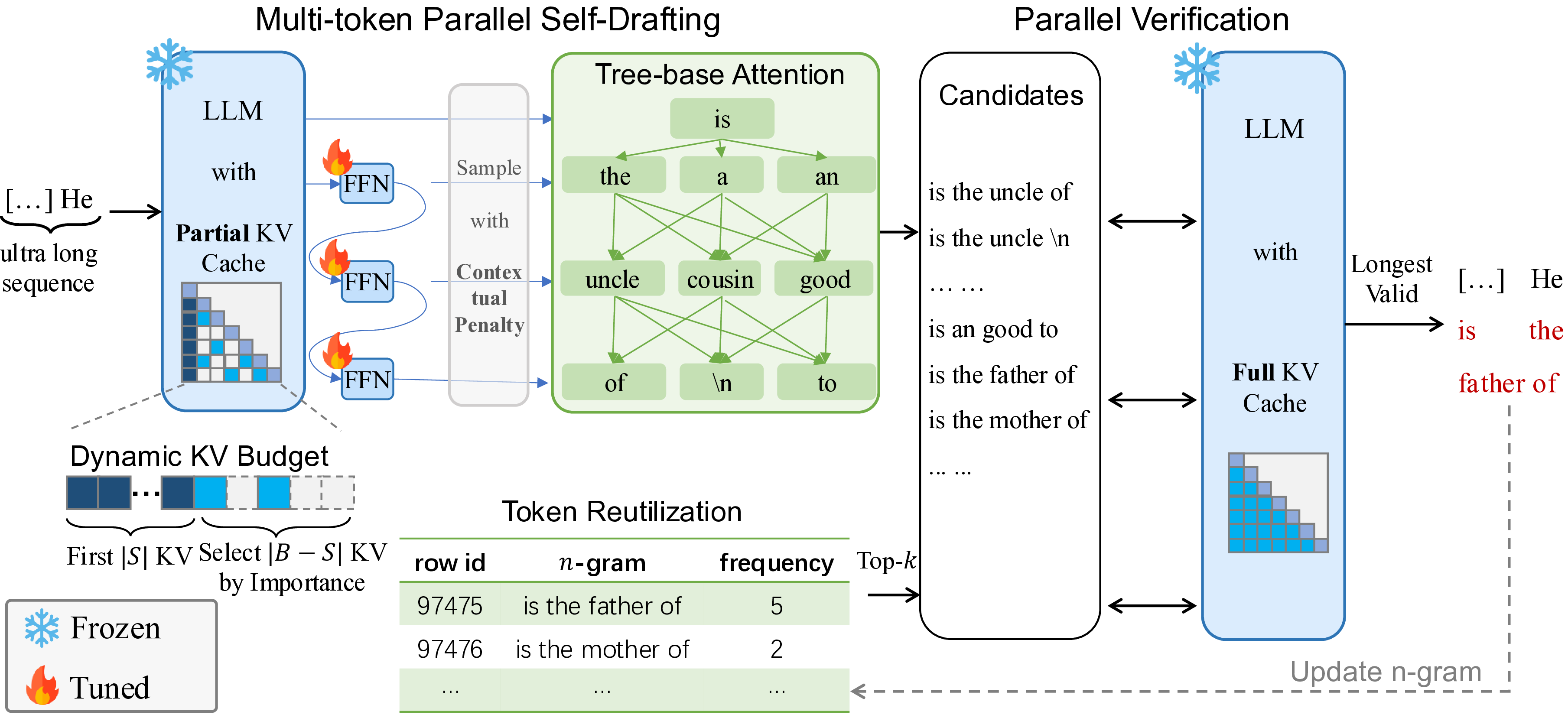
1. Multi-Token Generation & Token Reutilization
Instead of generating one token at a time, TokenSwift predicts multiple tokens in a single forward pass. Inspired by Medusa, it adds lightweight linear layers to the base model, and utilizes tree attention to enable Multi-Token Generation. To further boost efficiency, it reuses frequent n-grams (phrases) from earlier text, reducing redundant computations.
2. Dynamic KV Cache Management
TokenSwift intelligently prunes less important KV pairs while preserving critical context. It keeps the initial prompt’s KV cache intact and dynamically updates the rest based on importance scores derived from attention patterns.
3. Contextual Penalty and Random N-gram Selection
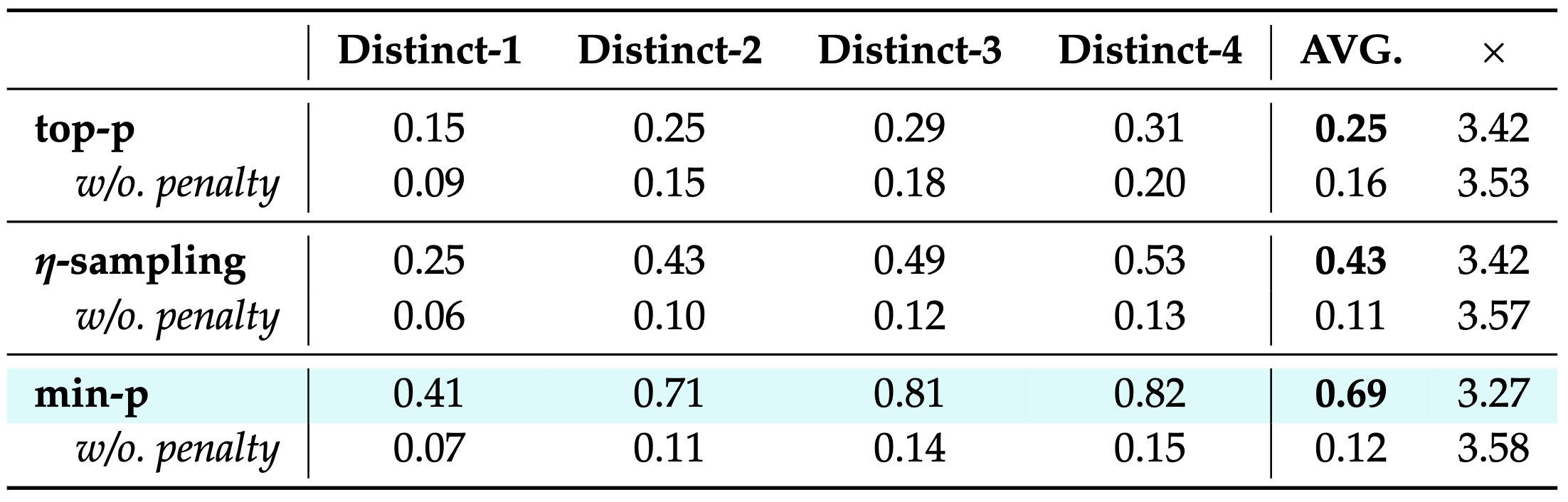
To combat repetition, TokenSwift penalizes recently generated tokens within a sliding window, nudging the model toward diverse outputs. This works alongside sampling strategies like Nucleus Sampling, min-, and -sampling
Results: 3x Faster, Scalable, and Robust
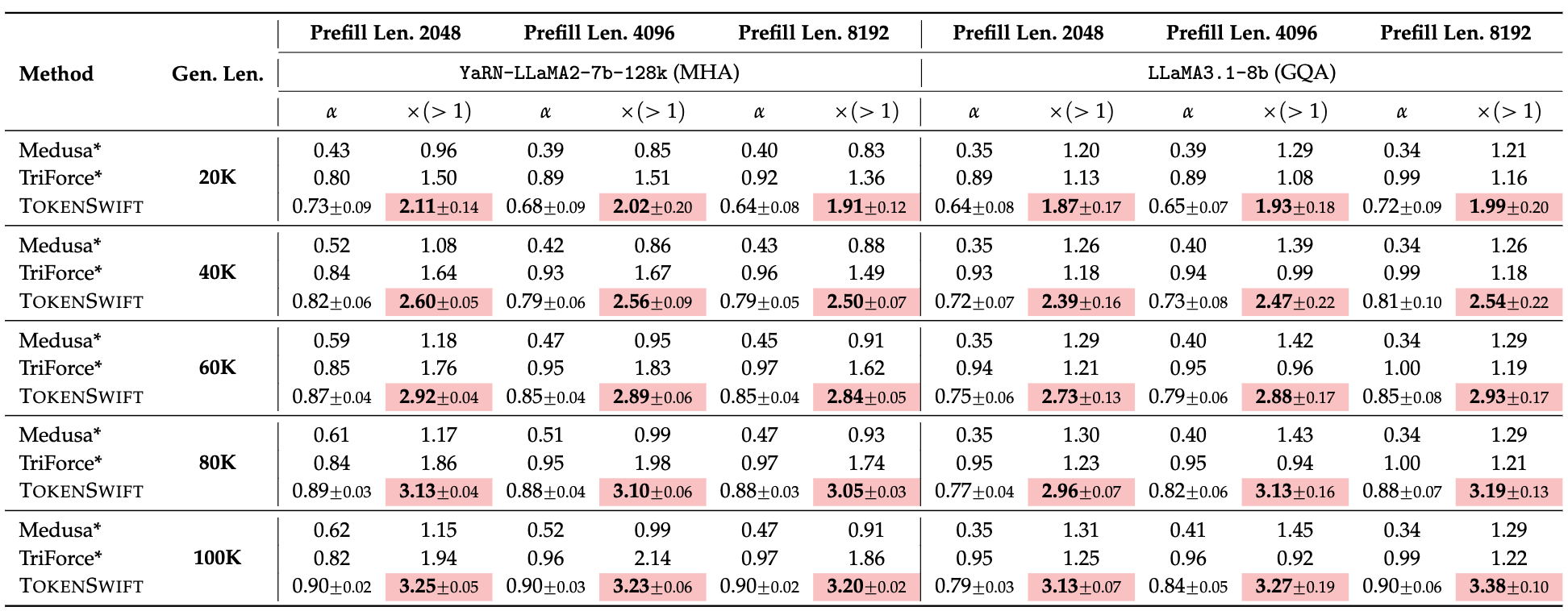
Table 1 and Table 2 are the main results, showing TokenSwift can consistenly achieve over acceleration across various model scales and architecture.


Citation
@inproceedings{wu2025tokenswift,
title={TokenSwift: Lossless Acceleration of Ultra Long Sequence Generation},
author={Wu, Tong and Shen, Junzhe and Jia, Zixia and Wang, Yuxuan and Zheng, Zilong},
booktitle = {Proceedings of the 42nd International Conference on Machine Learning},
year={2025}
}